
近日,星策开源社区 LLMOps meetup V3直播活动顺利举行,由星策开源和CSDN等多个平台同时播出,共吸引来14000+观众观看。管家婆最准一肖一码AIGC研究院执行院长、解放号副总裁韩鹏受邀参加并分享当前业界最为关注的大模型在企业场景中实际落地的案例和实践,还演示了基于JointPilot平台构建AIGC企业应用的典型模式、方法、工具和关键技术,小编整理了一下,为广大开发者带来超实用的AIGC应用落地干货。
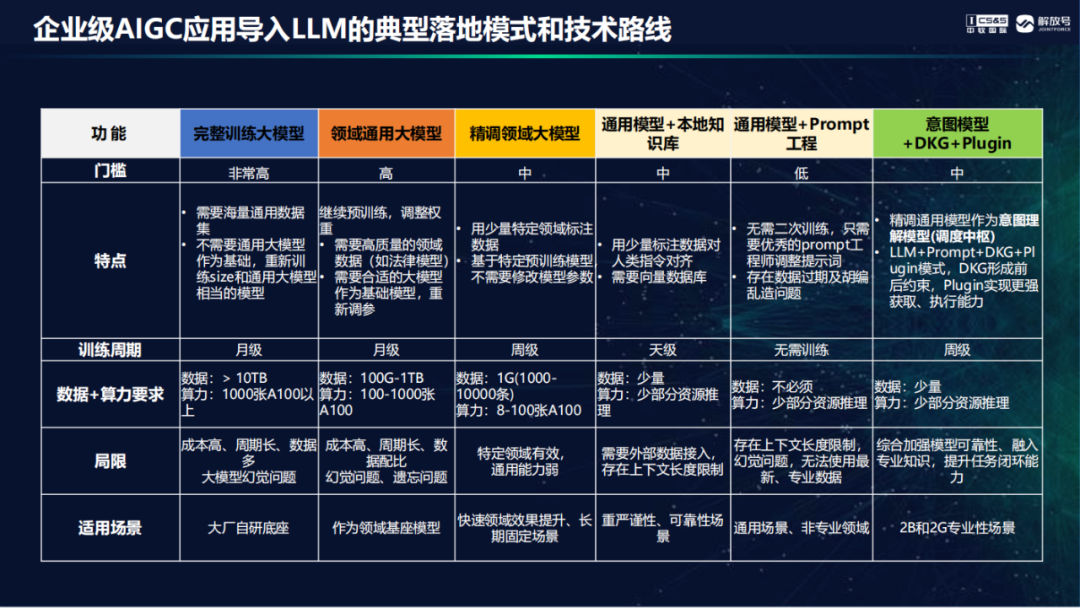
企业级AIGC应用导入LLM的典型落地模式和技术路线大模型落地的技术路线有六种,企业要综合考虑门槛高低、训练周期长短、算力数据成本要求等问题。经过多方研究和验证测试后,管家婆最准一肖一码AIGC研究院最终选择了“意图模型+DKG+Plugin”作为企业级AIGC应用导入LLM的典型落地模式和技术路线。这种模式有了能够本地部署的意图理解模型做为应用调度的中枢,通过DKG做模型的前后约束,并集成Plugin的能力,更适合于面向对数据安全、业务逻辑规则要求比较严格的政企行业应用场景。
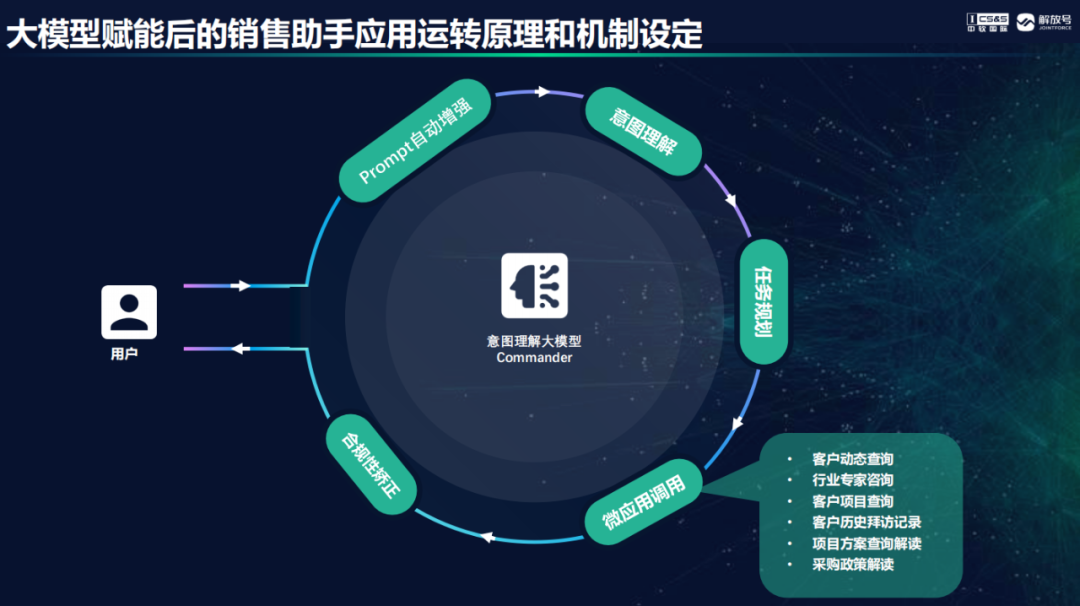
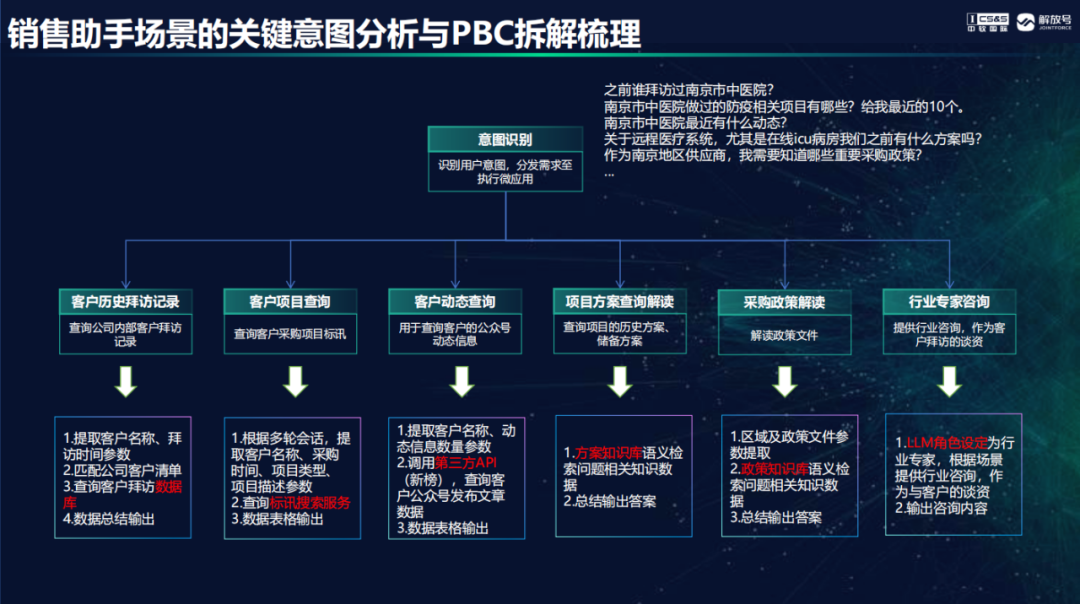
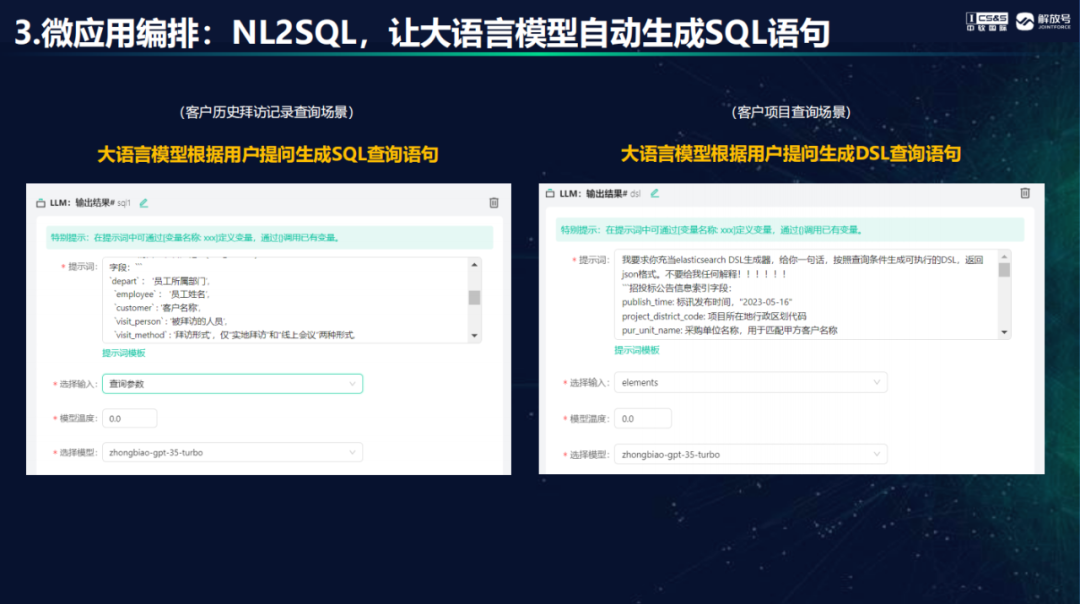
韩鹏以销售助手为例介绍了大模型赋能应用的运转机制。在传统工作场景下,销售在拜访客户前需要进行客户背调、项目收集及谈资等准备工作,在拜访客户后还需要详细整理内容形成拜访记录和工作总结,工作繁杂且耗时耗力。销售助手AI应用通过大语言模型赋能之后,生成一套运转的流程和机制,用大语言模型去完成意图理解,理解了用户的意图之后对用户指令进行任务拆分,分别调用不同的微应用去执行任务。最后输出时,销售助手也做了安全性的矫正,保障输出的结果是准确合规的。在思维链加持下大模型可以进行意图识别和任务拆解,通过长思维链的技术方式增强大模型的规划和推理能力,根据任务调微应用执行,同时使用内部沉淀及外部抓取的数据,集成各类通用及定制的能力,共同构建了以问答为基本交互形式的销售助手。销售助手帮助销售人员完成了客户拜访前的谈资和话术准备,让工作更高效精准。 怎么利用JointPilot Studio编排一个AI应用呢?JointPilot平台在应用开发方面提供一款新型增强的开发工具Studio和一种全新的应用组装方法。一个普通的业务人员可以使用开发者工具进行微应用编排。平台支持多种非结构化数据接入,支持各类文档导入,比如上传文档,通过向量数据库和大模型进行知识重构,构建采购政策、项目方案知识库;还可以调用模型的能力自动生成问答对在平台上预置,便于开发者快速调取;也支持行业专用词典的知识接入,帮助大模型理解专用术语。当然,在实际场景还会有一些结构化的数据需要接入到知识库,比如CRM系统的客户拜访记录数据,本地数据集、数据表的导入,各种Excel文件导入等等,这些结构化数据让大模型能够更懂企业场景私有的领域知识。大家可以使用JointPilot平台自动化的工具,快速实现百万级条目数据导入,大大减轻了手工导入数据和知识费时费力的烦恼。在微应用编排过程中,大模型需要访问各类数据库,包括关系数据库查询、数据集查询、文档知识库查询等,比如查询客户历史拜访记录,平台提供NL2SQL生成器等工具,方便用户通过Prompt工程让大模型生成SQL查询语句。
同时还要让大模型会用工具,通过自动化配置请求链接、接口参数等轻松实现API的调用,从而大幅降低用户应用生成的门槛。在对话场景中,我们需要通过角色设定来让大模型能够更好的理解特定身份的任务,比如销售助手中大模型在拜访前辅助销售人员进行准备工作梳理并提供鼓励,可以通过配置好的Prompt模板,来实现角色扮演的任务。那么,大模型是怎样像人一样会用大脑去思考用户提出的问题,怎样自动分发应用,自动化编排、自动化组装?这就需要训练出一个意图识别大模型作为应用调度的中枢,通过大模型来识别提取需求要素,作为数据服务参数,传递给要调取的应用。想要“炼制”更符合企业场景需要的模型,首先要选择一个基座模型,要准备数据集,还要有一套合适的训练方案。目前用的比较多的是SFT监督微调、LoRA 微调、P-tuning v2 微调方法。最后要对模型优化效果进行评估。整个训练过程会使用工具把很多脚本执行的碎片化过程,通过可视化界面实现全过程管理。数据集的选取、封装,以及具体参数的调整,都通过工具来完成。解放号总结出了一套训练大模型的心得,分享给各位开发者:1、鉴于每个模型的表现不太一样,选择一个合适的基座模型最重要。训练command模型最终选用百川大模型,它的优势是基于LLAMA做中文训练,在中文的表现很好。大模型尺寸选择会影响模型推理能力。2、数据集质量特别关键。尤其是在企业场景里,需要跟大量业务部门和业务人员一起做监督学习和数据标注,也可借用大模型来扩展增强数据集,使用instruction、input、output方式来整理。如果模型泛化能力弱,就需要增强训练数据多样性。3、精调的方案选择和场景相关度非常高。建议通过做多种方案对比测试看实际效果。可以用5%-20%的数据集作为测试数据来测试精调的任务,建议测试数据和训练数据要分开用,通过测试后再去跑全量的数据。当训练结果大量返回重复字符时,就需要调整数据集和训练参数,再重新做训练。4、尽可能训练小尺寸模型,这对部署成本控制非常关键。一般情况4-8个节点才能满足真正生产环境中使用的要求,所以在部署前尽可能做量化压缩优化,确保不损失太多性能的技术上降低资源的需求。这一期干货分享就到这了,相信小伙伴们还会有很多的问题想要交流,敬请继续关注我们。管家婆最准一肖一码解放号将在JointPilot平台的加持下,携手广大开发者,加速应用创新,共赢企业级AIGC应用未来!










 合作伙伴
合作伙伴

